设计以外,广告以内:函数方法篇
2021年|类型:编著|标签:专业理论
在设计领域, 我们梳理问题有很多种体验设计的工具,出发点都是从用户出发,去发现并定位问题,最终落地到解决方案。在机器学习领域,基于具体场景,我们看到了另一种解决问题的方法——函数方法。
通过样本、特征、评估构建业务
通过把需要解决的业务问题转化为数学函数,指从业务的角度描述输入、输出,把业务建模成定义域等于所有可能的要素组成的多维空间,值域等于{0, 1}、[0,1]或R的数学函数。这个函数,就是我们希望确定和输出的产品策略。
还是从那个预测西瓜甜不甜的例子入手:先选取若干西瓜作为我们的研究对象;我们可以看到西瓜有一些可以被表述的特点,比如西瓜的颜色、重量、瓜蒂大小、纹理粗细等等;切开之后咬上一口就知道它甜不甜。那上述业务就可以被描述为:
f(颜色、重量、瓜蒂、纹理) = 西瓜是否甜
我们把一部分西瓜的自变量和因变量带入函数,求得表达式;再通过另一部分西瓜去评估这个表达式,看看西瓜是否甜。在这个预测问题中,西瓜就是样本,颜色、重量、瓜蒂、纹理就是输入的特征,西瓜甜不甜就是输出的标签。于是,我们可以整理得到下面一组概念:
样本是指数据的特定实例,我们将样本分为有标签样本和无标签样本。
- 有标签样本同时包含特征和标签。我们使用有标签样本来训练模型。
- 无标签样本包含特征,但不包含标签。在使用有标签样本训练模型之后,我们会使用该模型预测无标签样本的标签。
特征是输入变量,即简单线性回归中的 x 变量。简单的机器学习项目可能会使用单个特征,而比较复杂的机器学习项目可能会使用数百万个特征。
标签是我们要预测的事物,即简单线性回归中的 y 变量。标签可以是西瓜甜不甜、小麦未来的价格、动物品种等等。
特征与标签分别作为输入与输出,组成一个完整的样本,即业务函数f(X)=Y中的X与Y。
模型定义了特征与标签之间的关系。模型生命周期的两个阶段:
- 训练是指创建或学习模型。也就是说,向模型展示有标签样本,让模型逐渐学习特征与标签之间的关系。
- 推断是指将训练后的模型应用于无标签样本。也就是说,使用经过训练的模型做出有用的预测 (y')。
评估是指判断业务函数在多大程度上接近理论上的最优解,或者多大程度上接近需要达成的业务目标的函数,这个过程我们称之为评估。
我们说的策略,即业务函数,业务函数由模型与参数共同组成。模型是基于一定的假设在函数空间中框定的一类函数簇,参数是在模型确认之后对函数的细节描述。当我们说上线一个新策略时,广义上可以指新的模型、新的参数、或者两者都有。
我们说的算法,指的是推断参数的方法。一般广义上提到的算法则包括了模型构建与参数推断的整个过程。
样本
选取原则
- 样本完整性。通常我们有数量多但不完整的样本,人工标注目的也是把不完整的样本转化为完整的。建模与评估有限使用与业务目标一致的样本。
- 业务目标一致性优先。
- 样本多元化。尽量多种样本获取的方法。
获取方法
内部样本
- 数据埋点与落库。主要针对样本数据,包括正样本与负样本。样本数据埋点与落库应当完整地描述样本输入与输出,尽可能忠实并详细地还原每个样本产生时的相关数据。
- 数据标注。从 0 至 1 的初创阶段,上线一个简单且成本低廉的基础策略后用样本闭环来持续收集样本,但上线初期效果或体验较差。量大可以交给数据运营、数据标注团队。
- 数据增强。在已有样本的基础上通过数据变换的方法进行扩充。
- 数据重组。根据样本特性,从已有的产品业务数据中筛选或构造符合条件的样本的过程。
外部样本
- 公开数据集。为了统一标准的建立,降低公众的数据获取成本,许多学者自发组织资源、完善和整理一些针对特定任务的样本。一份完整的数据源包括数据来源、描述以及每个样本的输入和输出。
- 抓取与众包。在别的平台抓取,像 reCAPTCHA 项目的众包。
- 采购与商务合作。注意政策环境以及出售方数据的所有权。
特征
选取原则
- 注重特征的时效性。不使用未来信息。
- 注重特征的获取成本。特征数据有一方数据、二方数据,这里涉及到采购成本。再来说说研发成本,特征数据也可以分静态特征和动态特征,静态特征大部分时候是不变的,更新频率较低,可以离线计算并存储在系统中已供使用,开发和维护成本较低且一般为固定成本;动态特征是一些相对动态的信息,用户访问时间、GPS 等与用户当前环境相关的上下文特征,近一周点击数、近一周消费金额等时间窗口特征,一般需要在线实时获取或频繁更新维护。
- 注重特征带来的收益。一方面,单个特征或一组特征的引入为评估函数带来的提升,往往意味着业务目标的提升;另一方面,特征的精选对模型稳定性的提升,特征数量的增加意味着样本分布的可能性呈指数级增加。
选取方法
- 基于业务知识的特征选择。
- 基于模型收益的特征选择。从提高模型收益的路径出发,又称封装法。N 个特征,就有 2ⁿ-1 个特征子集,最终可以选择出模型效果最好的特征子集。除了穷举,还可以启发式的方法:向前启发式搜索、向后启发式搜索、双向启发式搜索。
- 基于代理指标的特征选择。又称为过滤法。通过一些代理指标对特征进行筛选。代理指标不直接决定模型效果,更多的是通过描述特征的分布或关系对特征进行侧写。通常可以从两个方面来选择,一个是与特征X本身相关的指标,如覆盖率、方差;一个是度量特征X与标签Y之间关系的指标,如 Pearson 相关系数 (X、Y都是数值)、Fish 得分 (X数值、Y类别)、假设检验与方差分析分 (X类别、Y数值)、Pearson 卡方检验 (X、Y都是类别)、互信息 (KL散度)。
评估
模型评估包括离线评估和在线评估。
离线评估有可以分为评价指标和目标函数。评价指标是一个从整体上评估模型好坏的相对宏观的指标,同一类问题(分类、聚类、回归)的评价指标基本是一样的;目标函数更多用于最优计算,同一类问题不同模型的目标函数也是不一样的。
对于所有的样本数据,可以随机切分出一大一小两份数据,前者量大用于模型训练,我们称之为训练集;后者用于验证由前者得到的业务函数,我们称之为测试集。对于更复杂的模型,超参数也需要明确,迭代次网络层熟与节点数等。从训练集中再随机切分一块小的数据集,我们称之为验证集。
机器学习的本质就是函数预测,常见场景有:
- 回归问题:预测一系列特征映射到一个数值的函数
- 分类问题:预测从一系列特征映射到一个已知类别的函数
- 聚类问题:预测从一系列特征映射到一个未知类别的函数
分类问题的评估方法
AUC是一个模型评价指标,只能用于二分类模型的评价。对于二分类模型,还有很多其他评价指标,比如Logloss,Accuracy,Precision。AUC和Logloss基本是最常见的模型评价指标。在分析这一组指标之前,先看一个二分类问题的混淆矩阵。基于这个矩阵,我们可以分为基础指标和综合指标。

基础指标——值越大性能越好系列指标
准确率:反映分类器或者模型对整体样本判断正确的能力。
Accuracy = (TP + TN) / (TP + FN + FP + TN)
精确率:反映分类器或者模型正确预测正样本精度的能力,即预测的正样本中有多少是真实的正样本。
Precision = TP / (TP + FP)
召回率:也称为真阳率、命中率。反映分类器或者模型正确预测正样本全度的能力,增加将正样本预测为正样本,即正样本被预测为正样本占总的正样本的比例。
Recall = TP / (TP + FN)
特异率:反映分类器或者模型正确预测负样本全度的能力,增加将负样本预测为负样本,即负样本被预测为负样本占总的负样本的比例。
Specificity = TN / (FP + TN)
基础指标——值越小性能越好系列指标
漏报率:也称为漏警率、漏检率。反映分类器或者模型正确预测负样本纯度的能力,减少将正样本预测为负样本,即正样本被预测为负样本占总的正样本的比例。
MissRate = FN / (TP + FN)
误报率:也称为假阳率、虚警率、误检率。反映分类器或者模型正确预测正样本纯度的能力,减少将负样本预测为正样本,即负样本被预测为正样本占总的负样本的比例。
FalseAlarm = FP / (FP + TN)
综合指标——值越小性能越好系列指标
F1值:是精确率 Precision 和召回率 Recall 的加权调和平均。平衡 Precision 少预测为正样本和 Recall 基本都预测为正样本的单维度指标缺陷。
F1-Score = 2*Precision*Recall / (Precision+ Recall)
AUC:Area under Curve,从字面理解,就是一条曲线下面区域的面积。这个曲线叫ROC曲线。ROC曲线可以用于评估模型中那个效果更好。
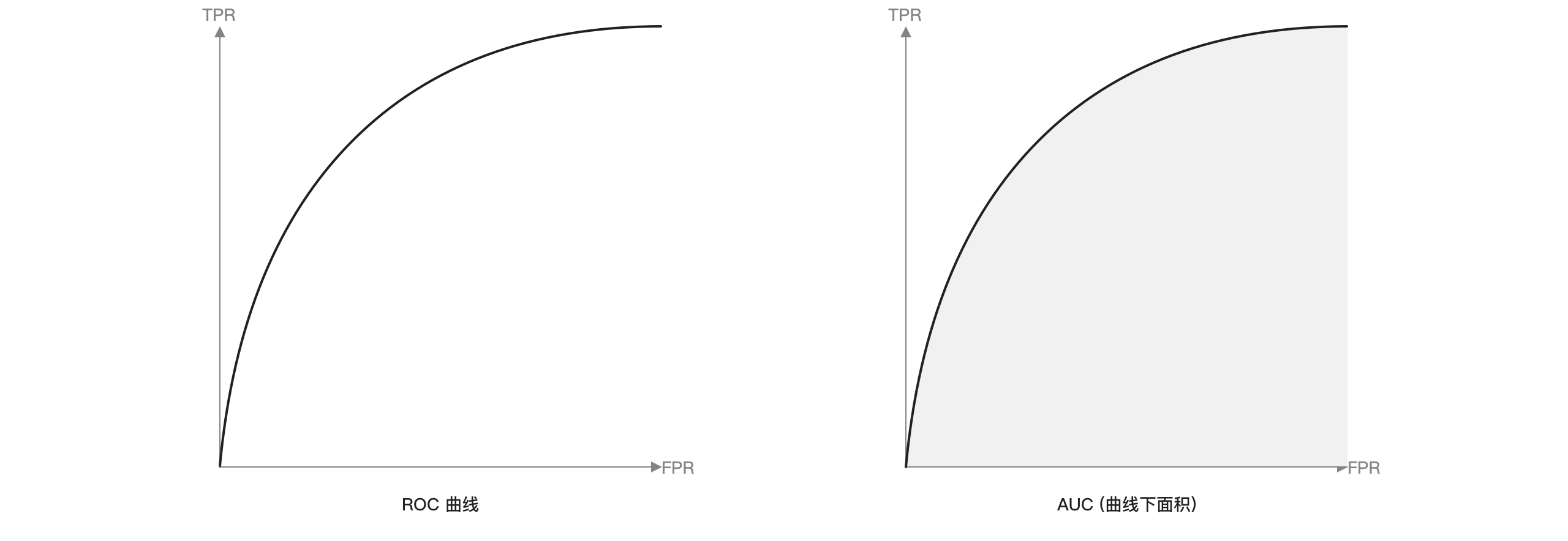
X轴为 FPR,Y轴为 TPR。我们希望分类器达到的效果是:对于应当预测为正例的样本,分类器预测为正例的概率 (TPR),要大于应当预测为负例的样本,而错误预测为正例的概率 (FPR)。
真正率 (TPR):是所有应当预测为正例的样本中,被正确预测为正例的比例。(召回率)
TPR = TP / (TP + FN)
假正率 (FPR):是所有应当预测为负例的样本中,被错误预测为正例的比例。
FPR = FP / (FP + TN)
Logloss 反映了样本的平均偏差,经常作为模型的损失函数来做优化。Logloss 越小越好,物理意义为:衡量预估 CTR 与实际 CTR 的拟合程度。
为什么 AUC 和 Logloss 比 Accuracy 更常用呢?因为很多机器学习的模型对分类问题的预测结果都是概率,如果要计算 Accuracy,需要先把概率转化成类别,这就需要手动设置一个阈值,如果对一个样本的预测概率高于这个预测,就把这个样本放进一个类别里面,低于这个阈值,放进另一个类别里面。所以这个阈值很大程度上影响了 Accuracy 的计算。使用 AUC 或者 Logloss 可以避免把预测概率转换成类别。
除此之外,在计算广告领域,我们实际要衡量的是每个用户对不同广告的排序能力,需要计算的是是对于每个用户的二分类结果,是一个更细粒度的二分类。这样传统的 AUC 就不太适用。于是就有了 GAUC (Group AUC),实际计算的是每个用户的AUC,通过加权平均得到 GAUC,从而降低不同用户之间的排序结果不好比较这一影响。
Lift 曲线:在不使用模型的情况下,我们用先验概率估计正例的比例;使用模型后,我们从预测为正例的样本子集中挑选正例。后者除以前者,就是Lift曲线。描述的是模型的预测能力“变好”了多少,值越大效果越好。
Lift = 精确率 / 正例占比 = [ TP / ( TP + FP ) ] / [ ( TP + FN ) / ( TP + FP + TN + FN ) ]
K-S曲线:K-S曲线的数据来源以及本质和ROC曲线是一致的,只是K-S曲线把真正率 (TPR) 和假正率 (FPR) 都当作纵轴,选定阈值当作横轴来观察。测量真正率 (TPR) 和假正率 (FPR) 之间的最大间隔距离。
KS值 = max ( TPR - FPR )
回归问题的评估方法
这里的回归指回归问题和模型,如线性回归 Linear Regression,决策树 Decision Tree Regression,随机森林 Random Forest Regression,深度学习 RNN 等等。即预测的标签为数值变量,比如金额预估、时长预估等等。我们通常用另一组指标来评估预测结果与真实结果之间的差异,主要有三种:
- 平均绝对误差 (Mean Absolute Error, MAE)
- 均方误差 (Mean Squared Error, MSE)
- 均方根误差(Root Mean Squared Error, RMSE)
聚类问题的评估方法
聚类问题相关的模型更多用于离线场景下的数据分析。因为不同聚类算法的目标函数相差很大,有些是基于距离的,比如kmeans,有些是假设先验分布的,比如 GMM,LDA,有些是带有图聚类和谱分析性质的,比如谱聚类等等。在实际业务中,我们可以通过人工标注等方法将其转化为分类问题。通过目标函数的改造来实现相互转换。
模型
判别模型
判别模型 (Discriminative Model),又称为条件模型,或条件概率模型。利用正负例和分类标签,寻找不同类别之间的最优分类面,反映的是异类数据之间的差异。即从特征 X 出发,试图直接学习出从特征 X 到标签 Y 的函数关系,包括决策函数 Y=f(x) 或条件概率分布 p(Y|X)。
决策树(Decision Tree):预测分段函数。选择特质时,常常用信息增益 (Information Entropy)。如果信息增益大,那么这个特征对分类很重要,决策树就是这么找特征的。对于分类问题,具体的优化目标主要有:ID3模型、C4.5模型、CART模型。
K-近邻(K-Nearest Neighbor, KNN):对于任意一个新样本,将其分类为与该样本距离最近的K个样本中类别最多的那个类别。
支持向量机 (Support Vector Machine, SVM):是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。
逻辑回归 (Logistic Regression):逻辑回归会生成概率,常用于二分类。许多问题需要将概率作为输出。LR是一种高效、简单的的概率计算机制。实际运用中可以返回原本的值或转换成二元类别。逻辑回归的损失函数是对数损失函数。除此之外,正则化在逻辑回归建模中极其重要,当有大量罕见的特征组合且每个样本中仅一个时,包含特征组合的高维度数据会出现过拟合。大多数逻辑回归模型会使用以下两个策略之一来降低模型复杂性:L2 正则化;限制训练步数或学习速率。
生成模型
生成模型 (Generative Model),又称为产生式模型。估计的是联合概率分布。用于随机生成的观察值建模,特别是在给定某些隐藏参数情况下。即从特征X和标签Y的联合分布p(X, Y)入手构建模型,进而推到出条件概率分布p(Y|X)。
朴素贝叶斯 (Naive Bayes):自变量 X 为离散的随机变量。对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别,一般可分为三个阶段:
- 准备工作阶段。根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
- 分类器训练阶段。计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。
- 应用阶段。使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。
线性判别分析 (Linear Discriminant Analysis, LDA):自变量 X 为连续的随机变量。LDA 是通过假设预测变量来自多元高斯分布得出的。在计算出该分布的参数的估计值之后,可以将这些参数输入贝叶斯定理中,以便对观测值属于哪个类别做出预测。LDA假定所有类别共享相同的协方差矩阵。
二次判别分析 (Quadratic Discriminant Analysis, GDA):LDA 有一个协方差相等假设,与 LDA 不同,QDA 的每个类别都可以拥有自己的协方差矩阵。当决策边界为非线性时,QDA 通常会表现更好。
参考资料
- https://zhuanlan.zhihu.com/p/67119176
- https://developer.aliyun.com/article/780784
- https://zhuanlan.zhihu.com/p/39435695
- https://zhuanlan.zhihu.com/p/31886934
- https://zhuanlan.zhihu.com/p/74874291
- https://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html
- https://www.cnblogs.com/xingshansi/p/6892317.html
- https://blog.csdn.net/zhaohang_1/article/details/92794489
© 2024 Xiang PENG. All Rights Reserved.