有的放矢的数据接入与数据应用
2023年|类型:平台产品|标签:设计服务效率|角色:产品策划、交互设计
背景
腾讯营销在腾讯广告(下称广告)和腾讯智慧零售(下称零售)两大领域中存在多个数据接入渠道。这导致了我们投入了不少的人力、时间去对接项目、治理数据、引导客户重新接入数据。
点击查看 Slide
什么是数据接入?
广告消耗超九成是 oCPA 广告,这是强依赖于广告主所接入的一方数据。上个月知数渠道接入了近 2,000 亿用户行为数据。那到底什么是一方数据接入呢?
客户基于自身一定的诉求,充分利用服务端优势,通过前端埋点采集和(或)后端收集数据,将指定的数据依照某种协议上报至服务端的数据传输流程,叫做数据接入。常见的接入方式包括JS上报、SDK埋点上报、API 接口上报,还包括以文件的形式上传至服务端进行解析。
一次完整的数据接入,短则两三个月,长则半年。
接入了什么数据?
接入的数据主要包括在不同的场景下(行为产生的容器,如应用程序、微信小程序等)用户行为序列所产生的数据。在广告和零售下,我们将数据描述的对象统一称之为实体,用户、订单、商品等都是实体。由实体构成了接入后的数据资产。
广告
- 用户行为数据:用户行为数据是指用户在应用程序、微信生态(小程序、公众号、小游戏)、网页、线下等场景发生的行为,由用户标识+行为类型+行为发生时间+行为参数(选填)构成。
- 用户属性数据:用户属性数据描述的是一个人的属性,如用户的性别、年龄、会员等级等,由用户标识+用户属性的形式构成。
- 人群包:将用于投放的人群,以ID标识,以 .csv 为格式,加密后上传至数据管理平台形成的资产。
零售
- 用户行为数据:用户行为数据是指用户在微信生态小程序发生的行为,由用户标识+行为类型+行为发生时间+行为对象构成。
- 用户属性数据:用户属性数据描述的是一个微信用户在零售中的属性,包括个人基本信息、会员信息、导购标签、消费状态等。
- 订单数据:包括销售单、退款单。
- 商品数据:包括商品SKU、商品SPU、销售信息、商品类目、组合商品、商品信息、商品评价。
- 卡券数据:包括卡券信息、用户领券信息、优惠券核销信息。
- 店铺数据:包括卖家信息、门店仓库。
- 公众号数据:包括公众号粉丝总量、公众号粉丝概要表、公众号图文源表、公众号粉丝基本信息。
- 群数据:包括企微群成员信息、群信息、群聊统计、联系客户统计。

一方数据接入是什么
问题
我们从广告和零售收到多层反馈,37手游的副总裁直接就说接入效果不好,我们的零售客户更是被繁杂的对接弄到崩溃。这数据接入问题到底出在哪?设计引导产品、运营按照接入前中后去梳理一下广告业务和零售业务的问题。
广告数据接治用现状
在广告业务中,点击付费的年代,我们是不依赖于数据接入的,点击行为数据在我们这里。随着 oCPX 的演进,优化目标越来越深,越发依赖于客户回传的行为数据,平台会利用转化数据做各个方向的数据应用,包括定向、粗排、精排、oCPX、归因、投放报表等核心模块。
对客户而言,数据接入有四个主要的功能触点,即人群包(腾讯广告知数)、数据源(腾讯广告知数)、归因(广告投放平台)以及 Marketing API。其中:
人群包,是以 .csv 等格式上传至腾讯广告知数,它是在广告投放流程中,以调价或定向为目的,对客户指定的不同人群进行出价。衍生形态包括单列人群包(即只有 ID 列)和多列人群包(即包含增益信息列可供下游读取)。
数据源,是以 JS 上报、SDK 上报或者 API 上报的形式,将客户的转化数据回传至广告平台。数据统计从 2022年09月27日至 2022年10月26日,其中:
- 近九成数据是通过API接口上报,超一成数据是通过SDK埋点上报。
- API 接口上报中,超八成数据来自网站。
- SDK 埋点上报中,超六成数据来自安卓应用,近四成数据来自苹果应用。
接入步骤:
- 注册开发者
- 创建数据源
- 选择接入方式,完成数据上报
- JS上报:全码(添加基础代码、添加行为代码),半码(添加基础代码、可视化配置行为代码),无码(可视配置基础代码、行为代码)。
- SDK埋点上报:通过行为数据源ID和数据接入密钥。
- API接口上报:创建应用程序、完成授权认证、使用 API 接口。
- 查看上报数据
数据源里面的数据有很多用途,其一便是归因。归因后的数据会作用到以机器学习为手段的各个环节。我们可以以归因为例来分析数据流。
旧版归因的操作路径是:
- 客户通过 Marketing API 注册开发者,获取密钥,用于开发。
- 客户通过广告投放平台创建点击检测,腾讯广告将点击日志回传给客户。
- 客户通过点击归因/渠道包归因(App推广专用)完成自归因,查看(过滤腾讯广告的)转化数据。客户通过腾讯广告知数创建数据源,将 (过滤后的)转化数据上报给腾讯广告,完成数据回传。
随着广告平台精细化运营的发展,各行业的特点不同、诉求不同,开始不断完善回传的数据,与 KA 客户深度合作,逐步发展成了全渠道、全链路的数据回传。在这个方向上,旧版归因存在以下几个问题:
- 体验割裂。用于归因的数据接入需要多平台协作。
- 字段受限。无法灵活地按照各类模型的要求回传有效数据。
- 容易误传。字符级的漏传、多传、传错。
这就要求带上了更多的信息,比如优化目标和深度优化目标。同时也推进了 oCPX 广告投放流程从“推广目标+优化目标+是否开启深度优化目标”,转向了“推广目标+行业链路+优化目标投放组合”的演进。
新版归因应运而生。主打灵活的一站式解决方案,即客户通过在广告投放平台创建归因规则(选择行业链路下的优化目标投放组合)时,会添加点击检测链接。通过约定指定格式的字符串,用以代表将来将要替换的字段位置,这个格式我们统称为“宏”,点击查看介绍。
与此同时,截止2022年11月03日仍有近七成 (67.31%) 客户使用旧版归因,旧版归因仍占比超过七成 (77.52%) 的消耗。旧版归因依旧需要一并兼容。复杂如归因,如何将新版归因与旧版归因一并考虑,也是一大难题。
oCPX 广告的优化下,各行业的客户回传转化数据给平台,讲究数据的准确性,优化方向是模型能尽可能地使用更多更准更实时的高质量数据。

广告数据接入治理应用现状
零售数据接治用现状
即微信生态(小程序、公众号、企业微信群等)下的智慧零售。我们发现在零售的数据接入过程中,因其经营分析的定位,众多应用上云,需要客户自主接入数据后才能实时地看清经营现状。客户结合自身的需求开通或采购相应的云上应用。这就有零售数据接入最大的优点:一接多用。为了满足全部都用得起来,除了云选联盟、优选联盟等几个场景,几近全部的零售应用场景都依照有数的要求接数。然而,有数在接数上有着非常严格的要求,而其他应用场景对字段在数量、校验上都没有这么复杂,导致客户费了很大力气接数之后,发现并用不上。除此之外,零售的数据接入,还有一些功能特性,比如为客户提供数据接入的日志查询,可以定位到每一条上报 PV 长什么样子,对客户都是很友好的。
接入步骤:
- 申请数据接入服务
- 获得账号信息与测试 Token,测试数据进入测试环境,正式数据进入测试环境
- 获得正式 Token,正式数据进入正式环境
- 开通应用与验收

零售数据接入治理应用现状
定位问题
接入数据的外部客户
对于接入数据的外部客户而言,广告客户和零售客户在接入过程中有下列问题:
数据接入不统一。
两大业务的接入流程、接入标准的差异,导致客户、服务商在与腾讯合作过程中,存在多头对接、重复上报、不规范上报的现象,直接导致数据接入的沟通成本高、执行效率低、数据质量差。
ig:客户开发一个应用,就有会数据接入的需求。据不完全统计,我们的接入文档有接近200份。当客户用了A能力,又想用B能力时,可能就得从A文档看到B文档。这些文档可能是部分是重复的,字段也是重复的。对客户的开发团队而言,会产生困惑。如果这个客户有多个团队,就产生了多次对接,造成大量的重复接入,这样的效率很低。
数据管理不完善。
数据接入间接导致多渠道之间难以高效利用,同时存在数据分散、字段标准差异等问题。客户、服务商在管理数据上体验欠佳。
ig:以“知数人群策略”为例,在2021年之前,因微信流量、非微信流量在父子广告id的差异、口径定义差异、中间表的时间含义差异及统计对象不同、数据缺失等问题,带来效果数据之间存在接近70%的Gap。
治理数据的内部团队
对于治理数据的内部团队而言,广告数据和零售数据在校验上都难以满足业务的当前要求:
广告数据校验松。
只有简单的工程校验,没有记录失败原因,无法溯源。重复上报也没有明确处理逻辑。处理逻辑也没有在文档中体现。作用系统后的校验逻辑不全、不清晰。
案例:平台最开始规定接入的数据主要是三类:为优化目标(转化目标),提供了归因数据的接入;为投放定向,提供了人群包数据的接入;为数据洞察,提供了行为数据的接入;这些数据历史上,在不同的团队治理与管理。各做各的,效率低,不互通。为了达到效果,行业运营就与客户协商,一开始大家通过自定义行为去传,不够了就在属性里面加。这就导致客户回传的数据参差不齐,也不好校验。
零售数据校验严。
因为零售在产品、平台、服务上都有对外触达的数据,各支线发展进程和自动化程度相距甚远,为了提升数据治理效率,以最严格的标准作为验收水准线,但其实造成了高投入、低产出的客情。
案例:除了云选联盟、优选联盟等几个场景,几近全部的零售应用场景都依照有数的要求接数,而有数的校验最严格。
使用数据的内部团队
对于使用数据的内部团队而言,对比两大业务,广告用得深,零售用得广:
数据链路关卡多。
每条链路都有不同的数据处理逻辑,流程环节多,中途会出现数据少了、多了、错了、慢了四大问题。
案例:某些环节出问题导致数据少,重试等操作导致数据多,格式转换篡改原始数据导致数据错,环节多了导致数据分发慢。
数据资源浪费多。
低效的消费。每个消费端都把数据拿过去,复制一份、冷备一份,造成了资源的浪费。
案例:以前的联合专区、归因和深度合作,是三条通路,就得存三份。后来合并成了两条,现在在推进成一条。
数据应用难理解。
下游的应用方对接入的数据难以理解。各个应用方对数据的要求也不一样。特别是在机器学习领域,模型训练与预测的数据折损大,各行业客户回传的转化数据的应用价值受到限制。
案例:陌生的理解。广告系统里,归因、模型、策略等消费端各有各的理解与用法。目标不一致,很容易就成了辛普森悖论。各说各的好,整体一看又不好。
这几类问题,可以进一步抽象成:
- 数据接入质量问题
- 数据接入效率问题
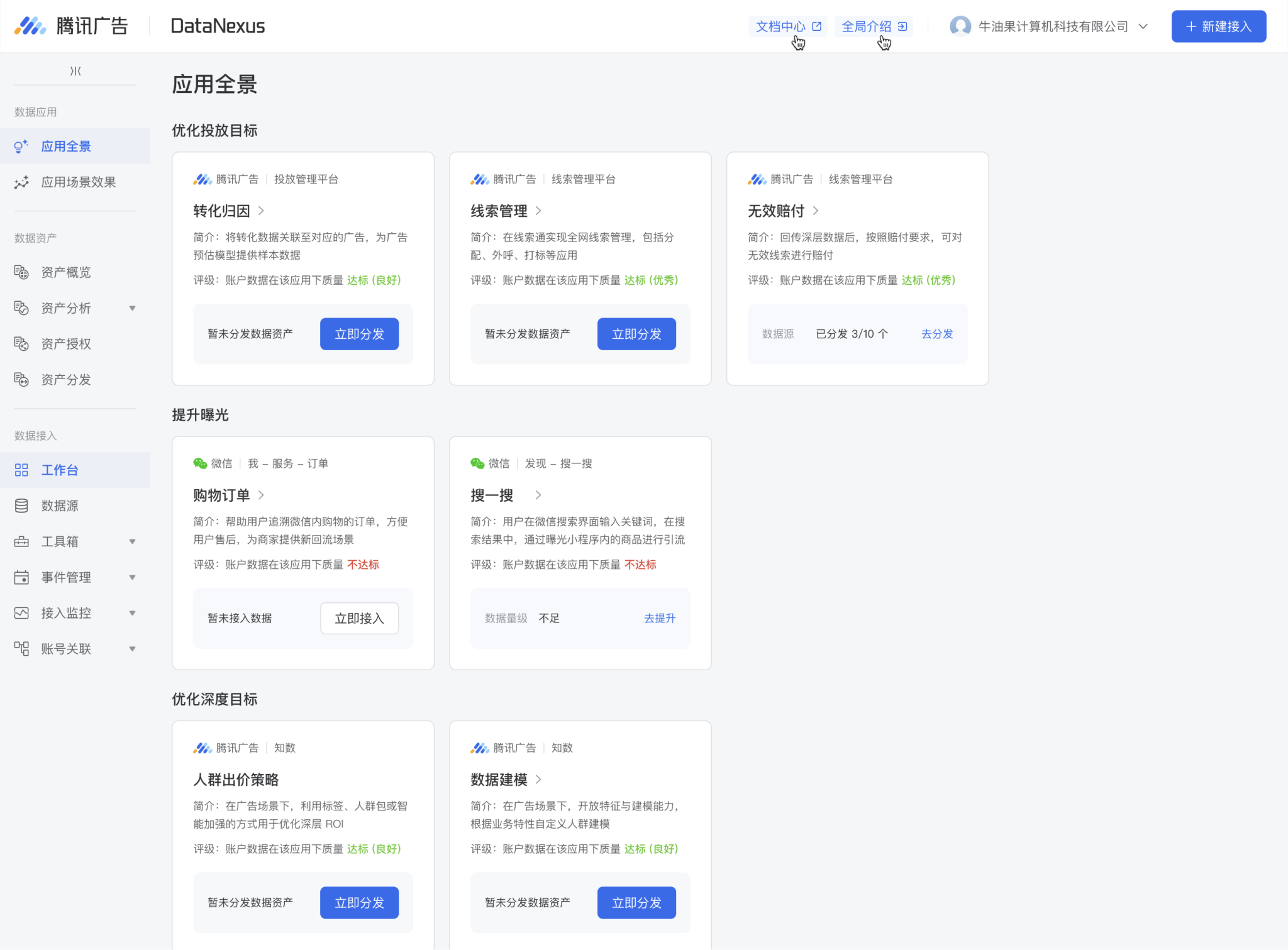
目标
基于这三类用户,我们尝试探索一种全域、全新的数据接入与应用分发的产品体验。既满足广告场景应用深、数据又多又准又实时的要求,又能满足零售场景应用层丰富,一接多用的要求。以广告和零售的数据为桥梁,为客户打造连通公域流量与私域流量的全域营销数据助手。
客户目标
在同一个腾讯平台,按照特定业务的数据要求,高效地完成高质量数据的接入。1 次接入,即可满足多种腾讯业务的使用。客户可以在同一个腾讯平台,按照特定应用场景的数据要求,完成数据接入即可分发,1 次接入即可满足至多 22 个应用场景。
业务目标
通过统一广告和零售,融合多渠道、多应用、多行业对数据接入的要求与标准,统一执行ETL服务和精准应用分发,为客户提供一站式数据接入与资产管理平台。真正实现即接即用,一接多用,以用促接,实现数据接入带来更多数据价值的正向循环。
设计目标
- 构建统一的数据接入与资产管理平台
- 提升数据的接入效率和接入质量
解决方案
第一个目标:统一的数据接入与资产管理
首先,在团队合并初期,大家都不熟悉,我们以设计冲刺的方式,引导广告侧和零售侧快速达成共识,得出信息架构。
- 什么是资产:原始资产是接入的数据资产,可用资产是清洗后的数据资产。
- 资产描述的是哪些实体:用户、商品、订单、卡券、门店、公众号、群……
- 资产的形态:包括数据源和文件,数据源需要单独开发,文件只需要上传即可
- 什么是应用场景:在某个腾讯产品下的具体能力、产品、服务等

信息架构
其次,我们制定了以用促接的设计方案。通过收集两大业务用数的应用场景后,进行分类,由公域到私域的营销目的、用户所感知的品牌与触点。我们就有了应用场景的设计。

如何组织信息
串到流程里,就是你要用什么,就接什么。

选择应用场景
这边还有一个“一接多用”的概念,已经接入了两个应用场景,意外满足了第三个应用场景。就不再需要重复接了。

一接多用
再次,资产管理,我们得先帮助客户解决资产在哪看的问题。也就是腾讯各接数平台间的关系。然后我们再解决管理问题。以前是针对资产的管理,是不带应用场景也不用分发的,因为就一个;现在是去建立资产与应用场景一对一的关系,从而实现精准授权与分发。
为用户提供平台联动场景的新手引导解决方案,传达各平台价值主张,灰度计划双端齐切,明确平台差异与价值点,支持未来与有数的联动。

跳转关系图
建立数据源/文件与应用场景之间一对一的关系,从筛选和批量提高操作效率。分发、授权的对象不再是数据源/文件,而是针对 <数据源,应用场景> 和 <文件,应用场景> 的精准授权与精准分发。
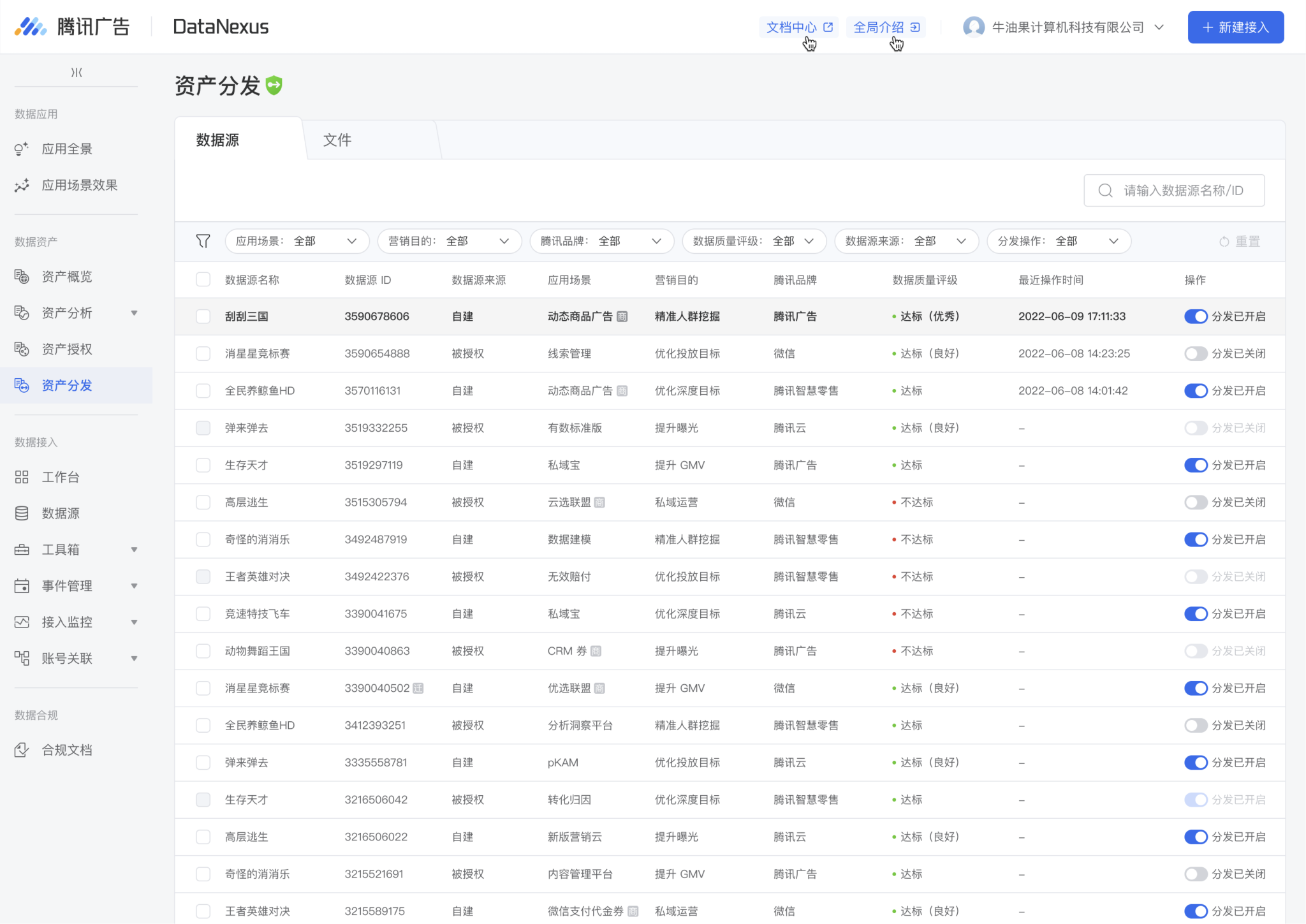

资产授权与资产分发
第二个目标:接入效率
通过量化接入字段和接入步骤来实现接入步骤少、接入操作少、接入时长短、重复接入少。
首先,接入方式取交集,字段取并集。这样就是最少的接入方式接入最需要的字段。

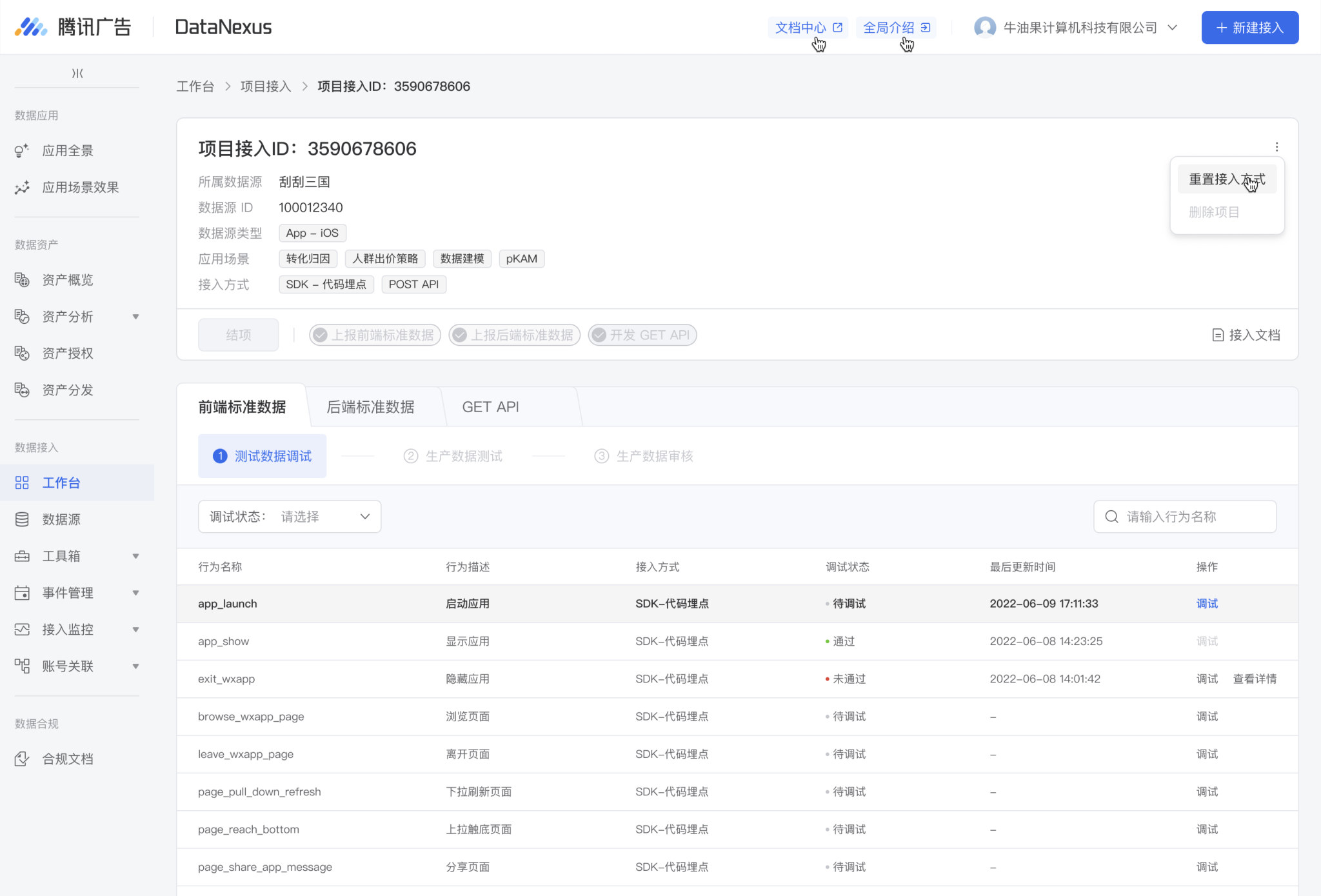
接入方式取并集,字段取并集
其次,为了解决那个提一个大包过去测试以及花1000块验证的问题,我们把测试拆成了二乘以二,没有测试数据进正式环境是为了避免数据污染。
- 定义:接入效率=接入量/接入时长
- 接入时长,可以按照接入步骤细分,定位每个环节卡点
- 接入量,即完成接入后的日均接入量

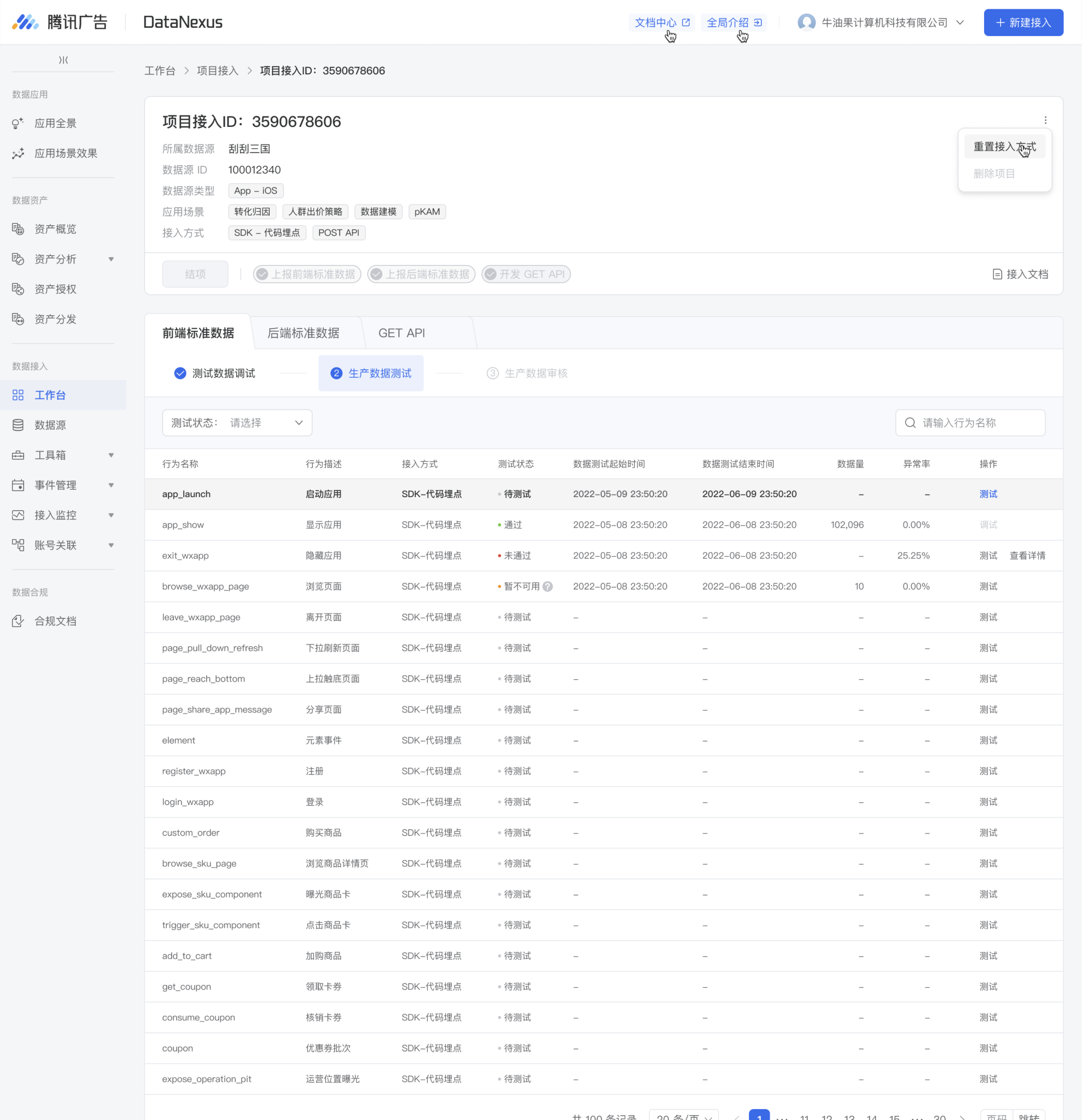

交叉送审,量化接入步骤
第三个目标:接入质量
难点在于底层逻辑的优化,核心包括数据模型的优化和校验规则的搭建。
通过数立方的一方数据治理的实践,数据侧基于内部实验的班车机制,搭建并验证了四元组(UserInfo, ItemInfo, ActionInfo, QualityInfo)的数据模型。其中 QualityInfo 将从下列维度进行衡量:
- 唯一性:是否存在重复记录
- 实时性:从业务发生到数据可用的间隔时长
- 准确性:数据是否与其对应的实体的范围及枚举一致
- 完整性:行完整:依赖正确的校验集对比是否存在缺失记录;列完整:是否存在缺失字段、记录
- 一致性:一个实体在不同数据集是否一致
通过行业调研,构建全新的校验规则(实体基础规则,应用场景规则,行业规则),目前共梳理 184 套,目前仍在按照优先级不断推进:
- 用户实体:(5 个广告应用场景 ✕ 270 种 Ops 行业)+(13 个零售应用场景 ✕ 全行业)= 148 套
- 商品实体:(1 个广告应用场景 + 10 个零售应用场景) ✕ 全行业 = 11 套
- 卡券实体:3 个零售应用场景 ✕ 全行业 = 13套
- 店铺实体:9 个零售应用场景 ✕ 全行业 = 9 套
设计能够做的,就是不断去优化字段所在的接入文档,完善文档信息。触点主要有两个:
- 首先,项目里面有一个常驻入口,随时可查阅的行业定制文档。
- 其次,文档中心,设计引导产品推导了新的信息架构,以解决文档的散乱。即使现在文档还存在登录前后是2套的问题。

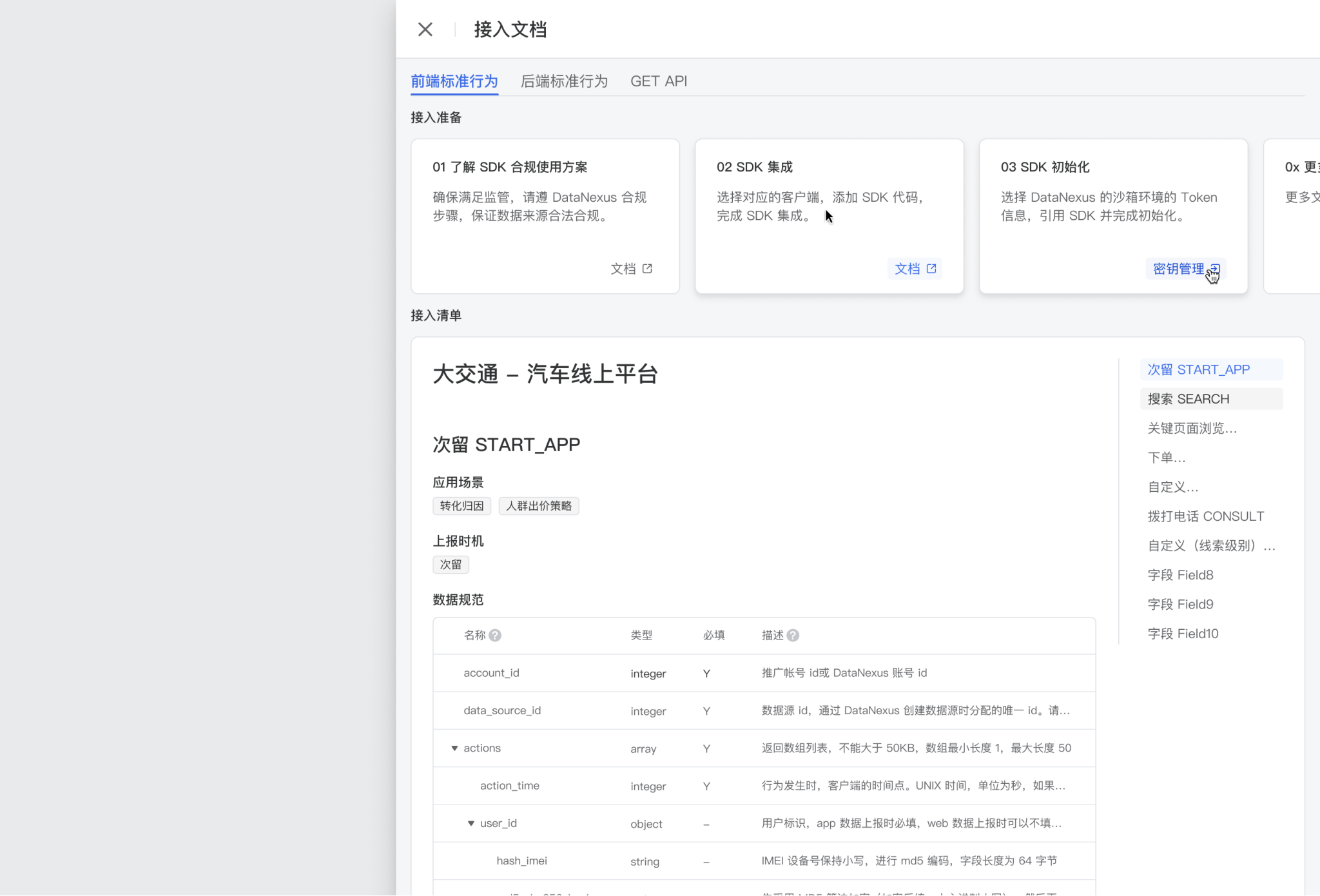
随时可查的行业定制文档,增量呈现的行业标准字段
效果
截止 2022 年底,DataNexus 覆盖了8000+客户,在平台可控的接入效率上,两大业务都从天级降至小时级。在接入质量上,也实现了GMV的显著提升。除此之外,作为设计师在项目初期把大家凝聚到一起也获得了项目层面的认可。不足的是,全量以及全量后的调研。

整体效果
写在最后
不论是对内治理数据,还是对外接入数据;不论是面向人还是面向机器。我们需要做的,是混乱之中创造秩序。做一个既能守护传统设计价值,又能为设计价值探索边界的设计师。
© 2024 Xiang PENG. All Rights Reserved.